
Rule-Based Sentiment Analysis on Twitter Data

Part 2: Sentiment Analysis
Why in the world would someone care about social media data?
With an abundance of social media, news articles, and opinion pieces available on the web, Data Scientists are able to utilize these resources in order to extract millions of text data. In this project, I am specifically looking at tweets from the 2020 United States Presidential Election. To read how I collected these tweets, please check out my previous post!
Extracting data from twitter is greatly beneficial because twitter is used to express opinions and engage with others publicly. From twitter, Data Scientists are able to find key words among tweets, analyze geographic differences in opinions about topics, detect bots on twitter, analyze user engagement for specific topics, and create a timeline of events from tweet data (Chen et al., 2020). As well, tweet data can even be utilized to make predictions such as the 2020 US Presidential Elections! Pretty amazing, right?
We as well know that social media influences opinions. Opinions are spread through following other accounts that tend to share a certain viewpoint with the use of resources, links, and more. In result, our opinions grow stronger towards that topic. The spread and influence of opinions on social media can positively and negatively impact society. An example of negative impact is the rise of hate groups and terrorist organizations through the help of social media. According to Christopher Way, Director of FBI, these dangerous organizations utilize social media platforms to recruit, radicalize vulnerable persons in the U.S., propagate its ideology, and create false personas on social media to discredit U.S. individuals and institutions.
We can see how analyzing and understanding the intricacies of social media can help pinpoint how, where, and why trending opinions spread. Alright, at this point you are probably thinking to yourself, “Wow! Data from social media is super cool!”
Purpose
For my project, I am focusing on the context of popular topics from collecting tweet data regarding the 2020 US Presidential election. The goal of this is to apply sentiment analysis and topic modelling to these tweets. Sentiment Analysis specifically is a Natural Language Process in order to detect and analyze opinions or attitudes within a text.
A few questions to answer with sentiment analysis and topic modelling:
- How do the majority of tweets perceive Trump and Biden in total versus for each state? Does the perception change from June 2020 to October 2020?
- What is the sentiment on specific topics that were important to the election such as COVID19, voter fraud, BLM, supremacist groups, Trump tax return, supreme court, anti-mask.
- How do tweets posted from a twitter account user with a large following perceive certain topics?
- What are the top 5 positively perceived topics versus top 5 negatively perceived topics?
These are questions that will be answered as I continue this project. For the rest of this post I will be focusing on the senttiment analysis methods.
Methods
Rule Based
Rule-based sentiment analysis calculates a sentiment score on a text based off implemented rules.
- TextBlob
- Vader Sentiment Analysis
Machine Learning
Machine learning algorithms can be utilized to label the sentiment. In order to do this, I need to first train the model with a pre-existing labeled sentiment as the independent variable. The drawback to this approach is that I would need to label the sentiment for each tweet for a large enough sample size in order to train and test the model successfully. The second drawback to this approach is that in this project, I would be the only person labeling the trained dataset which means there will be bias in labelling the dataset. This is because my viewpoint may be different then someone else and how I identify as negative or positive may be different for someone else. For now, I will put this approach aside and continue with rule-based sentiment analysis.
- SVM
- Naive Bayes Classifier
TEXT BLOB
Text Blob is a text processing package that works with part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more.
Features
- Noun phrase extraction
- Part-of-speech tagging
- Sentiment analysis
- Classification (Naive Bayes, Decision Tree)
- Tokenization (splitting text into words and sentences)
- Word and phrase frequencies
- Parsing
- n-grams
- Word inflection (pluralization and singularization) and lemmatization
- Spelling correction
- Add new models or languages through extensions
- WordNet integration
From TextBlob Sentiment Analysis, the sentiment returns a polarity and subjectivity score.
Polarity score output is a float between the range [-1.0, 1.0], where -1.0 is 100% negative and 1.0 is 100% positive.
Subjectivity is a float within the range [0.0, 1.0] where 1.0 is very subjective (influence by a personal feeling or opinion) and 0.0 is very objective (not influenced by personal feelings or opinion).
Step 1: Import libraries
from textblob import TextBlob
Step 2: Clean text data
Let’s take a look at a tweet example from the dataset:

Things to note about the text:
- Punctuation: ‘@’,’!’, ‘…’, ‘:’, ‘/’, ‘.’, ‘?’
- Capitalization
- Face Palm emoji which signifies frustration or disappointment
- @mention of twitter user realDonaldTrump
In order to improve the accuracy when processing the tweet data with TextBlob, I first clean the text by:
- changing uppercase letters to lowercase
- removing punctuation and emojis
- removing consecutive spaces
- removing hyperlinks
- removing newlines
- removing retweet account when tweets are retweeted.
Use Regex to clean the data:
# Create a function to clean text
def cleanTxt(text):
text = re.sub('RT[\s]@[A-Za-z0–9]+', '', text) # Removing RT and the account retweeted from
text = re.sub('https?:\/\/\S+', '', text) # Removing hyperlink
text = re.sub(r'[^\w\s]', '', text) # removes punctuation and emojis
text = re.sub(r'\s*<br\s*/?>\s*', '\n', text) # newline after a <br>
text = re.sub(r'\s+', ' ', text) # replace consecutive spaces
text = re.sub(r'^\s+', '', text) # remove spaces at the beginning
text = re.sub(r'\s+$', '', text) # remove spaces at the end
# make all text lower case
text = text.lower()
return text
After cleaning the text, the tweet now looks like this:

Step 3: Create a function to get the subjectivity and polarity
def getSubjectivity(text):
return TextBlob(text).sentiment.subjectivity
def getPolarity(text):
return TextBlob(text).sentiment.polarity
Step 4: Create two new columns ‘Subjectivity’ & ‘Polarity’
df['Subjectivity'] = df['Full_Text'].apply(getSubjectivity)
df['Polarity'] = df['Full_Text'].apply(getPolarity)
Step 5: Create a function to define sentiment by calculating negative as (Polarity < 0), neutral as (Polarity = 0), and positive as (Polarity > 0) analysis
def getAnalysis(score):
if score < 0:
return 'Negative'
elif score == 0:
return 'Neutral'
else:
return 'Positive'
df['sentiment'] = df['Polarity'].apply(getAnalysis)
After cleaning the text and applying TextBlob Sentiment Analysis the dataframe now looks something like this!

Step 6: Compare sentiment score before cleaning the data with after cleaning the data
I would like to check to see how many tweet Polarity Scores changed between the clean text and unclean text. For me, this is a sanity check to make sure there is a difference when cleaning the text dataset.
To do this, I calculate how many tweets changed its polarity scores after cleaning the text data.
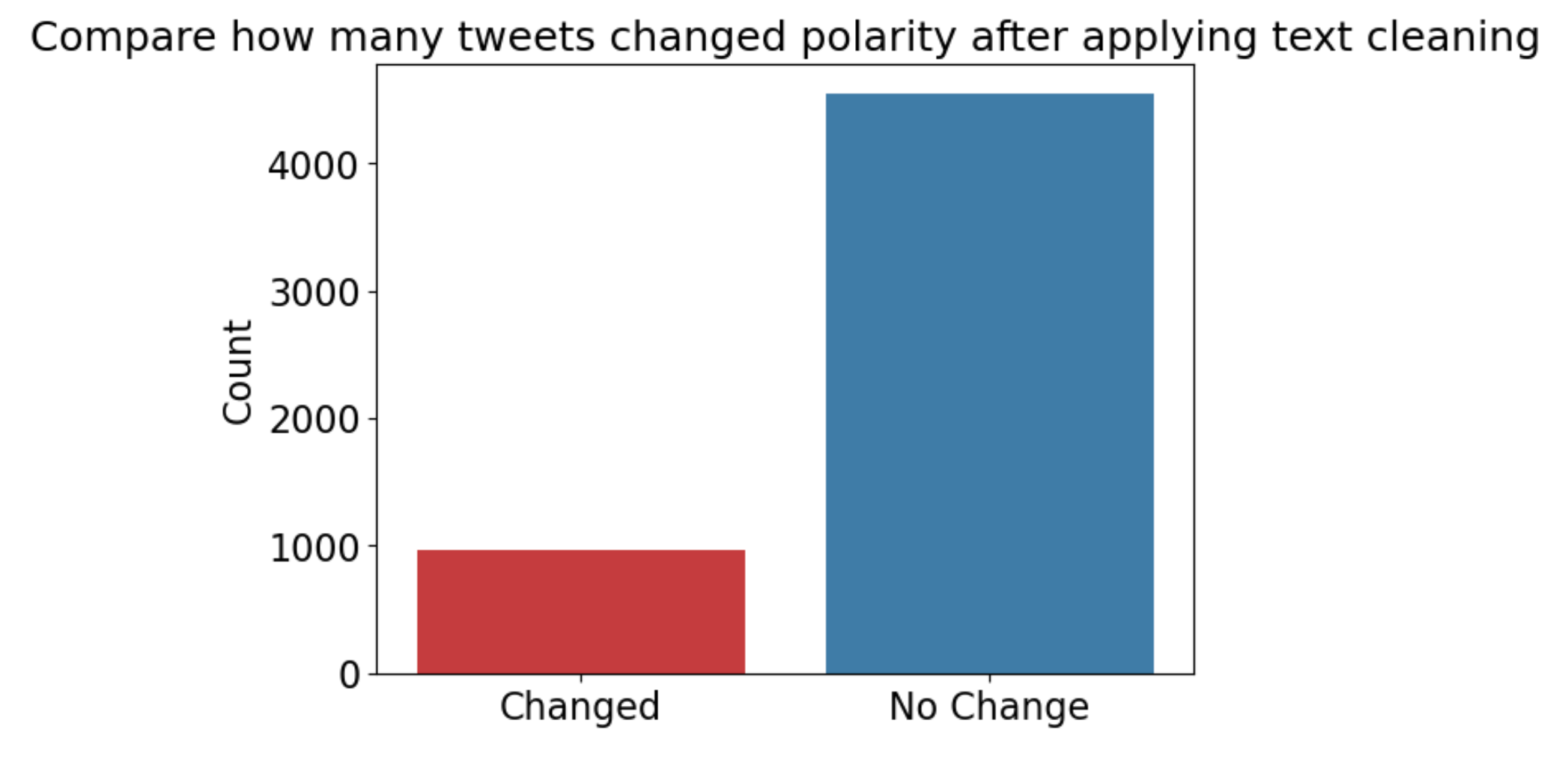
17% percent of the text changed its polarity score after cleaning the text
It is important to note that even if cleaning the text may not seem very significant, cleaning text is important for setting up the data because text data from tweets includes html links, extra space and lines, punctuation, and emojis which all may hinder TextBlob Sentiment Analysis scores.
Step 5: The number of tweets TextBlob identified as negative, neutral, and positive sentiment in August
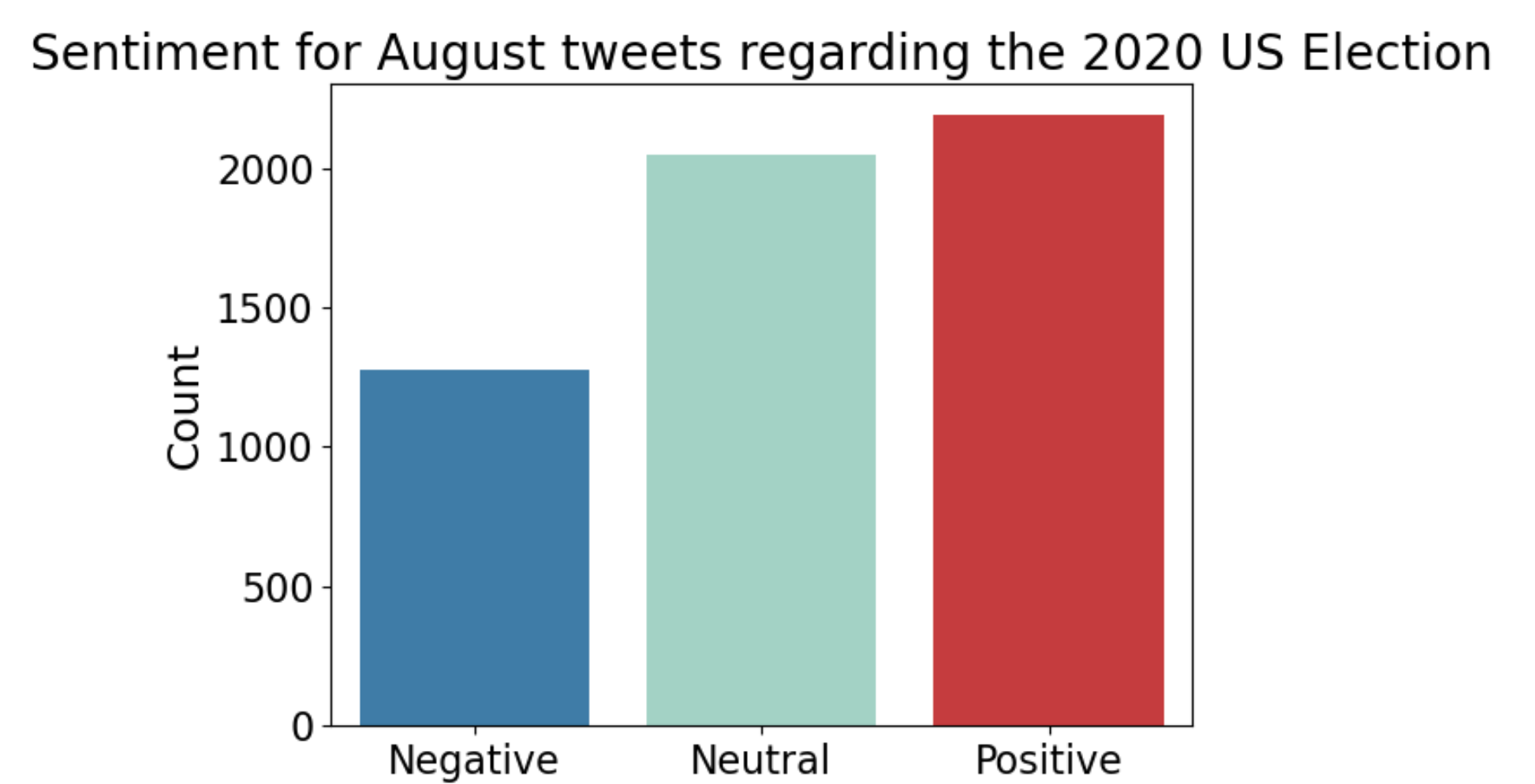
44.9% of tweets in August contain positive sentiment (2351 tweets)
25.4% of tweets in August contain negative sentiment (2142 tweets)
29.7% of tweets in August contain Neutral sentiment (1025 tweets)
I want to note that this analysis is a sample of tweets taken from August representing a much larger dataset (explained in previous blog post).
VADER SENTIMENT ANLAYSIS

While TextBlob Sentiment Analysis is a great tool to use, identifying the sentiment in text from social media adds an extra level of complexity compared to identifying sentiment within reviews, online news articles, or books. Social media text is complex because there are emojis to express feelings, acronyms (LOL OMG LMAO ROFL WTF ASAP), intentionally misspelled words like sux -> sucks and fav -> favorite. There are as well slang words that are used on social media such as yolo, muah, haha, woohoo, and using punctuation to make an emotion or face such as (: (; <3. These complexities in social media need to be accounted for when identifying sentiment with rule-based algorithms. Luckily, computer scientists from Georgia Tech, C.J. Hutto and Eric Gilbert developed a package called Vader Sentiment Analysis which takes into account many of the edge cases found in social media.
Vader Sentiment Analysis is another lexicon rule-based sentiment analysis tool that was specifically developed for social media text. Vader Sentiment as well accounts for speed and performance which is important for large datasets such as thousands or millions of tweets.
Score is computed by summing the valence scores of each word in the lexicon, adjusted according to the rules, and then normalized to be between -1 (most extreme negative) and +1 (most extreme positive).
Examples of typical use cases for sentiment analysis, include proper handling of sentences with:
- typical negations (e.g., “not good”)
- use of contractions as negations (e.g., “wasn’t very good”)
- conventional use of punctuation to signal increased sentiment intensity (e.g., “Good!!!”)
- conventional use of word-shape to signal emphasis (e.g., using ALL CAPS for words/phrases)
- using degree modifiers to alter sentiment intensity (e.g., intensity boosters such as “very” and intensity dampeners such as “kind of”)
- understanding many sentiment-laden slang words (e.g., ‘sux’)
- understanding many sentiment-laden slang words as modifiers such as ‘uber’ or ‘friggin’ or ‘kinda’
- understanding many sentiment-laden emoticons such as :) and :D
- translating utf-8 encoded emojis such as 💘 and 💋 and 😁
- understanding sentiment-laden initialisms and acronyms (for example: ‘lol’)
Step 1: Install Packages and instantiate
import nltk
nltk.download('vader_lexicon')
from nltk.sentiment.vader import SentimentIntensityAnalyzer
sid = SentimentIntensityAnalyzer()
Step 2: Clean Text
This time when cleaning the text, I do not change all letters to lowercase. This is because vader sentiment analysis takes into account uppercase letters. Specifically, if a word is in all capitalize this suggests emphasis on that word. For example: HURRAY! WIN! FAIL!
This time I specifically input which punctuation to remove from the text. For example, I do not remove exclamation marks ! because Vader Sentiment Analysis as well takes into account for exclamation marks.
# Create a function to clean the tweets
def cleanTxt(text):
#initializing punctuations string
text = re.sub('RT[\s]@[A-Za-z0–9]+', '', text) # Removing RT and the account retweeted from
# Remove hyperlinks before punctuation is important
text = re.sub('https?:\/\/\S+', '', text) # Removing hyperlink
# define punctuation
punc = '''()-[]{};:'"\, <>./?@#$%^&*_~'''
# Removing punctuations in string
# Using loop + punctuation string
for ele in text:
if ele in punc:
text = text.replace(ele, " ")
# One last clean with removing spacing
# After removing punctuation, consecutive spacing may be present
text = re.sub(r'\s*<br\s*/?>\s*', u'\n', text) # newline after a <br>
text = re.sub(r'\s+', u' ', text) # replace consecutive spaces
text = re.sub(r'^\s+', u'', text) # remove spaces at the beginning
text = re.sub(r'\s+$', u'', text) # remove spaces at the end
return text
Step 3: Perform Vader Sentiment Analysis
df['scores'] = df['full_text'].apply(lambda review: sid.polarity_scores(review))
df['compound'] = df['scores'].apply(lambda score_dict: score_dict['compound'])
df['comp_score'] = df['compound'].apply(lambda c: 'pos' if c >=0.05 else ('neutral' if (c < 0.05 and c > -0.05) else 'neg'))
Check out the table after applying Vader Sentiment Analysis!
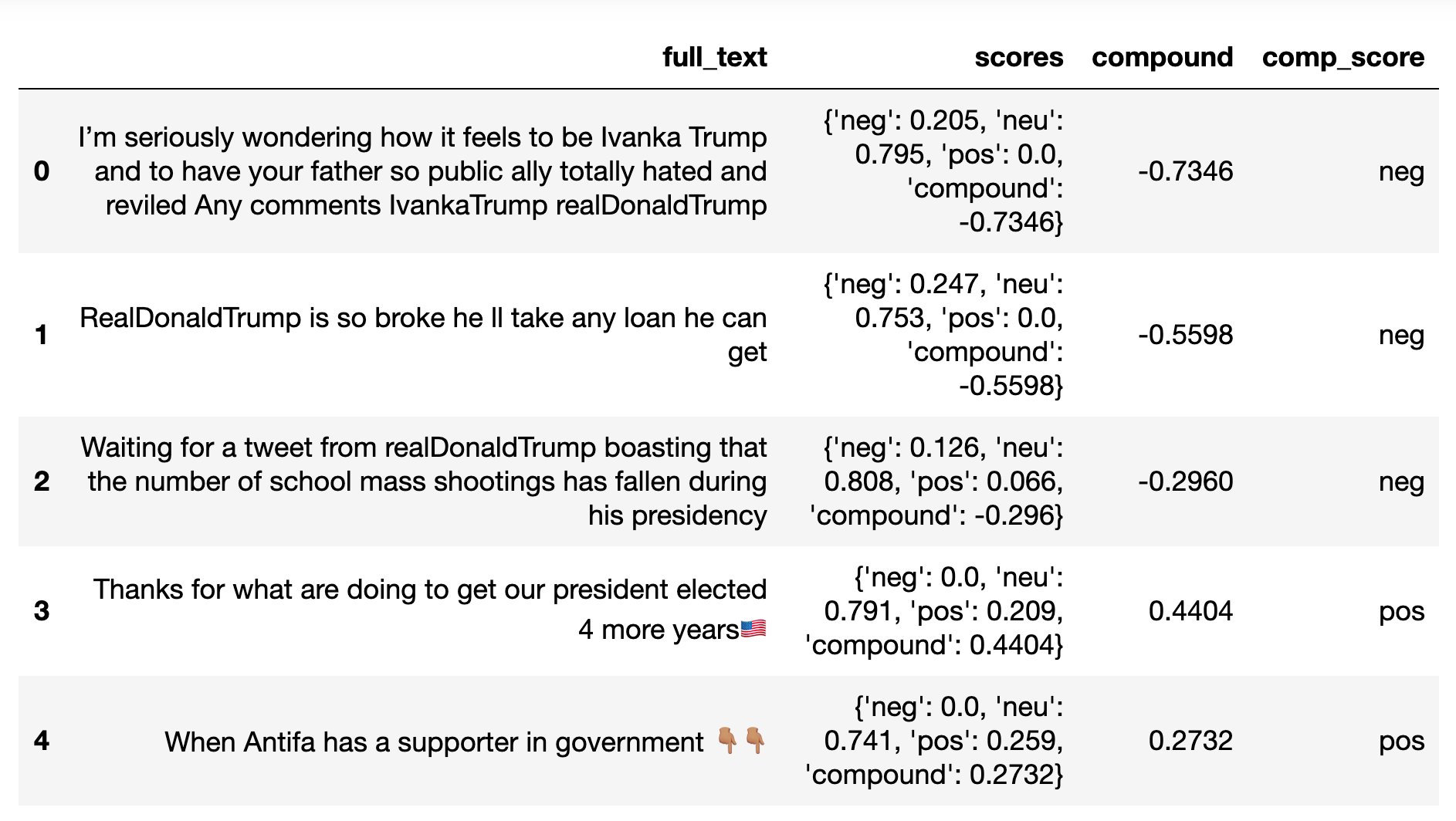
Step 4: Sanity Check on cleaning data
Let’s do another sanity check and compare how many tweets changed its compound score before and after cleaning the text data.
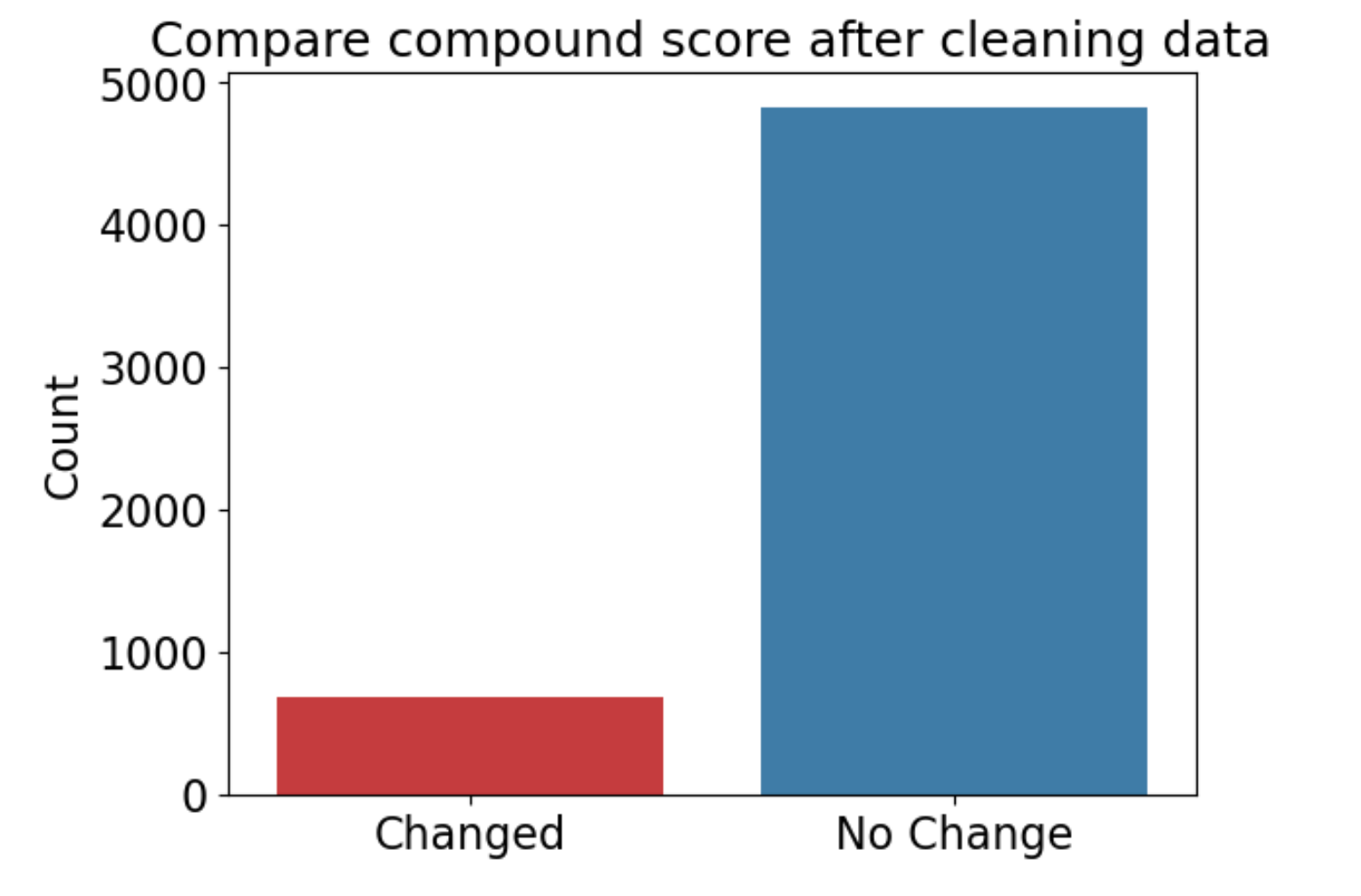
12% percent of the text changed its compound score after cleaning the text
Step 5: Compare distribution of tweets for negative, neutral, and positive sentiment in August
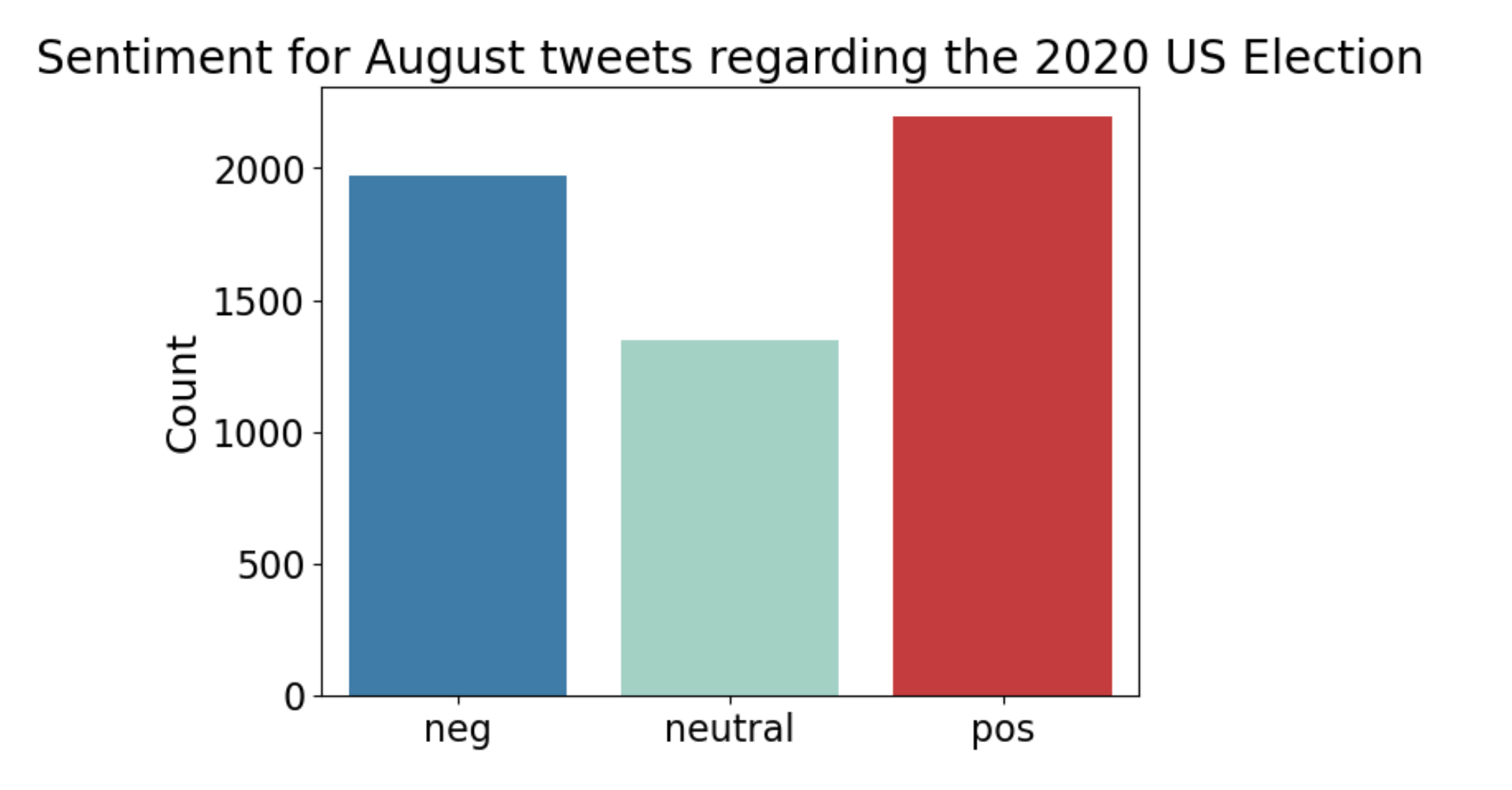
42.6% of tweets in August contain positive sentiment (2351 tweets)
38.8% of tweets in August contain negative sentiment (2142 tweets)
18.6% of tweets in August contain Neutral sentiment (1025 tweets)
I want to note that this analysis is a sample of tweets taken from August representing a much larger dataset (explained in previous blog post).
Examples positive tweets from August
Win win win win win F🤬k everything else Win win win win WIN
Dear realDonaldTrump I m 68 years old I was a Republican but now I m doing EVERYTHING I can to make sure JoeBiden wins in November YOU WILL NOT STEAL MY SOCIAL SECURITY BENEFITS amp YOU WILL NOT KILL MY POSTAL SERVICE UNDER UNDER ANY CIRCUMSTANCES Sincerely Grandma Grit
Today it was my great honor to proudly accept the endorsement of the NYCPBA! I have deeply and profoundly admired the brave men and women of the NYPD for my entire life New York’s Finest are truly the best of the best — I will NEVER let you down! MAGA
KellyannePolls GOD BLESS YOU🇺🇸 Sweet KellyannePolls U SHINED LIKE A BRIGHT MORNING STAR ⭐️ May The Lord Bless You amp Keep You In His Care🛡 We Will Be Praying For You🙏🏻 You SPOKE The Truth For Millions To Hear And We Know♥️🎚♥️ Thank You Our Love For You Is Great realDonaldTrump🩸 GODWINS
Dear Mr President As you honor and celebrate the life of your best friend and brother Robert please know that millions of Americans are praying that you and your family feel the Presence of God and the Peace that only He can bring realDonaldTrump DonaldJTrumpJr EricTrump
Examples of negative tweets from August
Pissed off about schools Blame Trump Pissed off about college football Blame Trump Pissed off about 165 000 dead Blame Trump Pissed off about an economy still on its back Blame Trump He didn’t listen didn’t prepare didn’t lead He lied He fucked up Blame him
realDonaldTrump Maybe the root of evil is drugs Drugs distort the mind into thinking there is no other way Then sets the place for prostitution robbing stealing murder Every kind of evil gives way to a life of misery and chaos Which causes destruction and no responsibility
atlpackfan2 onlytruthhere realDonaldTrump Take “Christian” off your profile It’s profane vain for hate intolerance racism pride falsewitness lying resentment impatience cruelty idolatry warmongering arrogance cheating amp antiChrist attitudes acts to rule your heart mind amp life Look to yourself!
Seriously how can anyone with half a functioning brain say JoeBiden is a danger to America when we have the most self serving moronic grifting misogynistic ugly as fuck no heart no brain uncaring constitution killing pussy grabbing punk ass bitch as president now
realDonaldTrump Tucker Carlson is a racist and a brat that they gave a platform to so he can spew his racism OBAMA and the other presidents did the right thing dump trump did the wrong thing as usual Carlson and trump 2 pieces of crap sad sad miserable people you are go get a real life racist
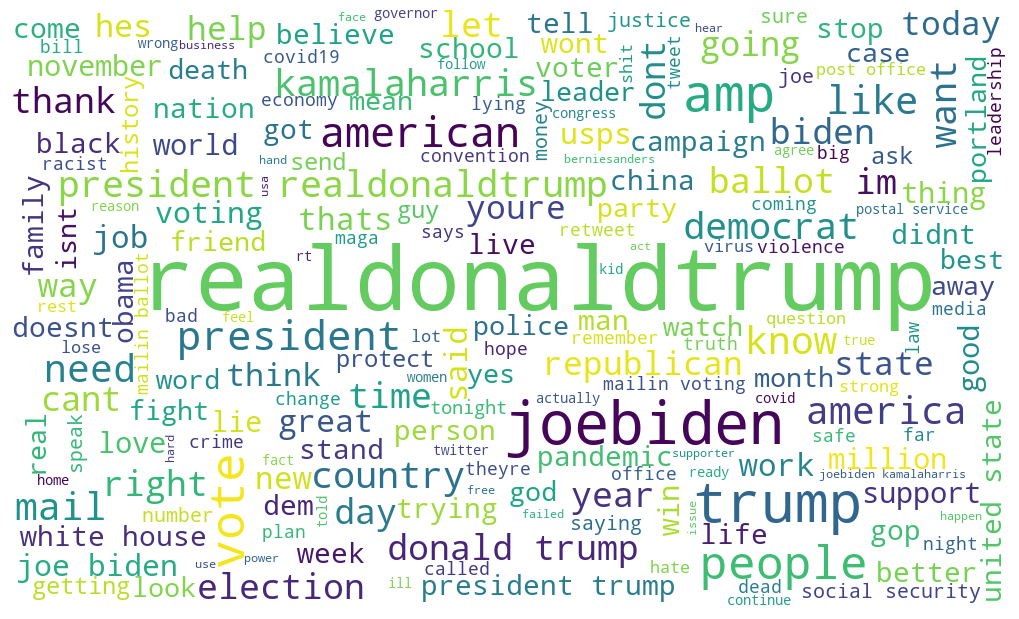
Word Cloud
A word cloud is a great visual tool because it helps visualize important words.
Before performing topic modelling, we can actually start to view which topics were frequently expressed in August. Below is a word cloud of the most frequently used words from the Tweets posted in August. The larger the font size the more frequent the word is used. We can see here that realdonaldtrump is the most freuqnet word. Other popular topics includes Joe Biden, american, people, president, voting, support, police, democrat, ballot, Kamala Harris, justice, country, mail, white house, social security, united states, school, black, racist, covid19, death, and november.
What’s next on the agenda?

Ok, I have now cleaned the the text data, applied Vader Sentiment Analysis to label the sentiment for each tweet. What’s next on the agenda?
Next stop is Top Modelling! Well sort of. First I will need to prepare the text data even more before running the topic models which will be discussed in my next blog post 😉.
With the combination of Topic Modelling and Sentiment Analysis, I will be able to start to form a story of the topics discussed and identify a sentiment trend towards that subject throughout the election.
References
Chen E, Lerman K, Ferrara E Tracking Social Media Discourse About the COVID-19 Pandemic: Development of a Public Coronavirus Twitter Data Set JMIR Public Health Surveill 2020;6(2):e19273 URL: https://publichealth.jmir.org/2020/2/e19273 DOI: 10.2196/19273 PMID: 32427106 PMCID: 7265654
Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
Wray, Christopher. “Worldwide Threats to the Homeland.” Federal Bureau of Investigation, 17 Sept. 2020, www.fbi.gov/news/testimony/worldwide-threats-to-the-homeland-091720.