
Stemming vs Lemmatization

Part 3A: Text Preprocessing for Topic Modelling
I love the word Lemmatization because the syllables, consonants, and vowels that make up the word lemmatization form a sound that makes me smile. I like Natural Language Processing (NLP) because I like to think about languages as a structure, pattern, and rhythm. Through this process, I can take a sentence and visualize it. Like a fun puzzle, languages are messy at first, but a comprehensive picture forms when the right pieces fit together.
I remember sitting in my high school English literature class with multiple sentences written on the board. We broke down each sentence and identified part of speech to understand how a word’s structure influences a sentence’s meaning. The act of breaking down a sentence to understand the structure falls under the discipline of linguistics. While as individuals, we can break down sentences and identify meaning, it becomes difficult and almost impossible to do so with large text documents such as 100,000,000 tweets or 100,000 news articles.
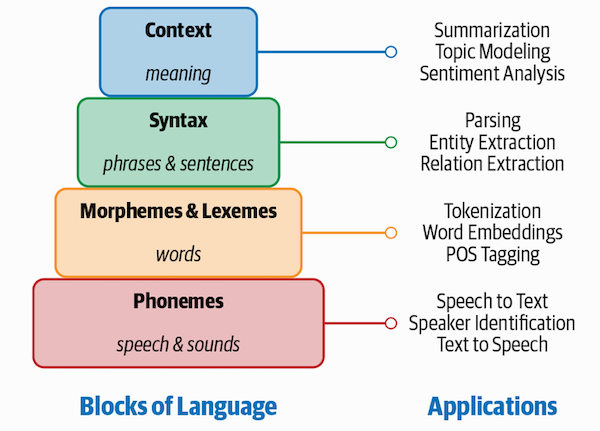
I love this figure taken from the textbook “Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems” by Vajjala, S. et al. 2020. The image shows that context, syntax, morphemes and lexemes, and phonemes are the language blocks. A variety of packages from NLTK, Spacy, TextBlob, and more, are Natural Language Processing applications that identify each language block. For example, to determine the context (meaning) with NLP, we can apply Topic Modelling and Sentiment Analysis.
Definition of Natural Language Processing
Natural Language Processing is part of the machine learning/AI pipeline. A variety of tasks are applied to process text data and format it so that the computer can read the data and perform analysis.
In this blog post I will discuss stemming and lemmatization, a pre-processing method for text data so that the text is ready to process for machine learning and rule-based algorithms. Specifically, in regards to topic modelling with the use of Twitter text data. This blog post is Part 3 in a series of posts in regard to collecting twitter data on the US Presidential Election.
Why use stemming and lemmatization?
Each document contains a vector of words (terms). Sentence tokenization separates each word into a matrix where each term is a feature. For example, if a sentence (Document 1) contains the term sit, and Document 2 has the term sitting. The two terms will end up as two separate column features even though the meaning is the same. However, if we reduce the word sitting to its root word sit, then the document matrix is reduced.
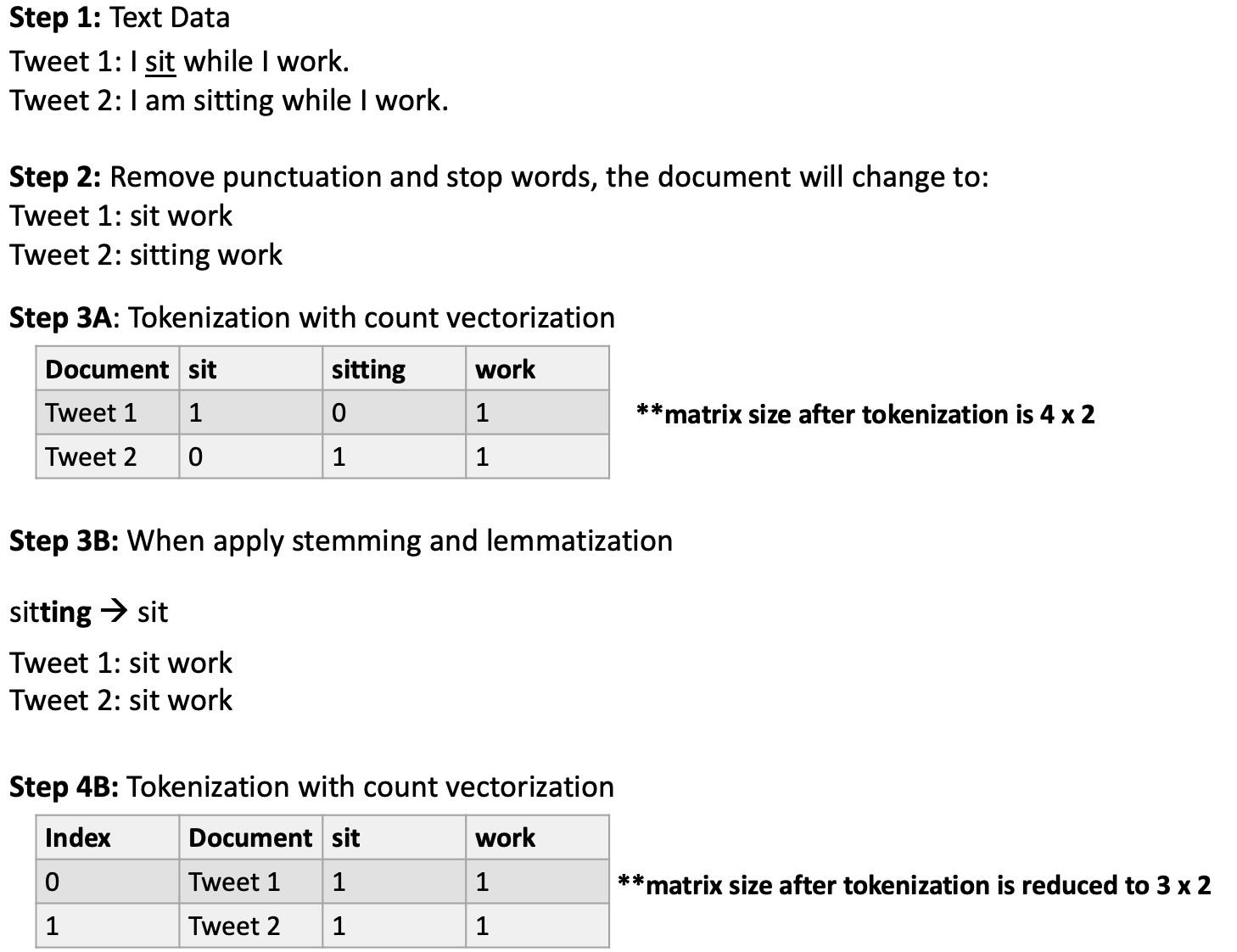
Stemming and Lemmatization are two different approaches for stripping a term within a document so that a document matrix reduces and the complexity of data decreases. Reducing the size and complexity of a model helps achieve model accuracy and reduce computation memory and time.
Stemming

Stemming is a text processing method in which a term reduces to its “stem” or simplest form by removing suffixes from the term such as (-ED, -ING, -ION, -IONS, -S). Suffixes are removed specifically for IR performance, not for linguistic meaning (Porter, 1980).
Types of Stemming:
- Porter Stemmer
- Lovinus Stemmer
- Paice Stemmer
Stemming removes case letters at the end of a word. For example, when applying stemming to the word catastrophe the ‘e’ at the end of the word is removed.
catastrophe –> catostroph
Significance of stemming:
Stemming can be beneficial when developing search engines for query matching and feature space reduction when training a model (B., Sowmya V et al., 2020).
Example rules of Porter Stemmer:
SSES —> SS
caresses —> caress
IES —> I
ponies —> poni
SS —> SS
caress —> caress
S —>
cats —> cat
Import and instantiate Porter Stemmer:
# Import NLTK
import nltk
nltk.download('wordnet')
#import stem package
from nltk import stem
from nltk.corpus import wordnet
# stemmer
porter = stem.porter.PorterStemmer()
Let’s see some examples of how Porter Stemmer is applied:
# Create a word list
word_list1 = ['play', 'playing', 'played']
word_list2 = ['feet', 'foot', 'foots', 'footing']
word_list3 = ['organize', 'organizing', 'organization']
word_list4 = ['benefactor', 'benevolent', 'beneficial']
word_list5 = ['universe', 'university']
print("['play', 'playing', 'played'] -------------------->", [porter.stem(word) for word in word_list1])
print("['feet', 'foot', 'foots', 'footing'] -------------> ", [porter.stem(word) for word in word_list2])
print("['organize', 'organizing', 'organization'] -------> ", [porter.stem(word) for word in word_list3])
print("['benefactor', 'benevolent', 'beneficial'] -------> ", [porter.stem(word) for word in word_list4])
print("['universe', 'university'] -------> ", [porter.stem(word) for word in word_list5])
Output:
[‘play’, ‘playing’, ‘played’] ——————–> [‘play’, ‘play’, ‘play’]
[‘feet’, ‘foot’, ‘foots’, ‘footing’] ————-> [‘feet’, ‘foot’, ‘foot’, ‘foot’]
[‘organize’, ‘organizing’, ‘organization’] ——-> [‘organ’, ‘organ’, ‘organ’]
[‘benefactor’, ‘benevolent’, ‘beneficial’] ——-> [‘benefactor’, ‘benevol’, ‘benefici’]
[‘universe’, ‘university’] ——-> [‘univers’, ‘univers’]
Pros for stemming
- Remove sufixes
- Reduce the size and complexity of data
- Reduce variance in models which can cause overfitting.
Cons for stemming
Stemming is too good at extracting the root word. One might say that stemming “butchers” the terms in a document. Stemming will take a word like organize and shorten it to organ which has an entirely different meaning. Same with the word University, which will stem to univers, again shortening the word to a word that is not the same meaning. When deciding to use Porter Stemmer, determine how important are the words meaning versus reducing the data’s complexity to your model and analysis.
Lemmatization

Lemmatization labels the term from its base word (lemma). This method is a more methodical approach for ensuring word reduction does not lose its meaning.
A. NLTK Lemmatization
# import lemmatizer package
from nltk.stem import WordNetLemmatizer
Examples of how Lemmatization is applied:
print("['play', 'playing', 'played'] -------------------->", [lem.lemmatize(word) for word in word_list1])
print("['feet', 'foot', 'foots', 'footing'] -------------> ", [lem.lemmatize(word) for word in word_list2])
print("['organize', 'organizing', 'organization'] -------> ", [lem.lemmatize(word) for word in word_list3])
print("['benefactor', 'benevolent', 'beneficial'] -------> ", [lem.lemmatize(word) for word in word_list4])
print("['universe', 'university'] -------> ", [lem.lemmatize(word) for word in word_list5])
Output:
[‘play’, ‘playing’, ‘played’] ——————–> [‘play’, ‘playing’, ‘played’]
[‘feet’, ‘foot’, ‘foots’, ‘footing’] ————-> [‘foot’, ‘foot’, ‘foot’, ‘footing’]
[‘organize’, ‘organizing’, ‘organization’] ——-> [‘organize’, ‘organizing’, ‘organization’]
[‘benefactor’, ‘benevolent’, ‘beneficial’] ——-> [‘benefactor’, ‘benevolent’, ‘beneficial’]
[‘universe’, ‘university’] ——-> [‘universe’, ‘university’]
We can see here that Lemmatization is more conservative about trimming a word then in stemming. University does not change to universe and organize/organization does not change to organ.
Handling plural in lemmatization
lemmatizer.lemmatize("ponies")
lemmatizer.lemmatize("caresses")
lemmatizer.lemmatize("cats")
ponies —> pony
caresses —> caress
cats —> cat
Understanding Lemma
To better understand how lemma applies within linguistics, let’s take a trip down memory lane and recall verb conjugation.
Conjugate ‘To Be’
Present Tense:
I am
You are
He/She/It is
We are
You are
They are
Past Tense:
I was
You were
He/She/It was
We were
You were
They were
Thus, the lemma or lemmatization of AM, IS, ARE, WAS, and WERE is BE.
Code test:
print('I am ---> To', lemmatizer.lemmatize("am", pos="v")) #v is for verb”
print('You are --> To', lemmatizer.lemmatize("are", pos="v")) #v is for verb”
print('He is --> To', lemmatizer.lemmatize("is", pos="v")) #v is for verb”
print('They were --> To', lemmatizer.lemmatize("were", pos="v")) #v is for verb”
I am —> To be
You are –> To be
He is –> To be
They were –> To be
Note: In NLTK lemmatization, the part of speech (pos) needs to be defined. In the example above, I define the pos as “v” for verb. If the pos parameter is not specified, then the default is set to NOUN.
Complex verbs in NLTK Lemmatizer
Has the capability to identify base words from complex verbs. See example below:
lem.lemmatize('beheld', pos = 'v')
lem.lemmatize('withheld', pos = 'v')
lem.lemmatize('flung', pos = 'v')
beheld —> behold
witheld —> withhold
flung —> fling
Adverbs in NLTK Lemmatizer
# adverb
print('farther', lem.lemmatize('farther', pos = 'r'))
# superlative adverb
print('farthest', lem.lemmatize('farthest', pos = 'r'))
# adverb
print('loudly', lem.lemmatize('loudly', pos = 'r'))
# superlative adverb
print('loudest', lem.lemmatize('loudest', pos = 'r'))
Output
farther —> far
farthest —> farthest
loudly —> loudly
NLTK Lemmatizer can handle most adverbs, such as the words farther and loudly. However, adverbs that end in ‘est’, also known as superlative adverbs, is not supported by NLTK Lemmatizer. Therefore, loudest does not change to loud and farthest does not change to far.
Adjectives with different endings
# comparative adjective
print('closer', lem.lemmatize('closer', pos = 'a'))
#superlative adjective
print('closest', lem.lemmatize('closest', pos = 'a'))
# comparative adjective:
print('smaller', lem.lemmatize('smaller', pos = 'a'))
# superlative adjective
print('smallest', lem.lemmatize('smallest', pos = 'a'))
# Dry
print('drier', lem.lemmatize('drier', pos = 'a'))
print('driest', lem.lemmatize('driest', pos = 'a'))
Output
closer close
closest close
smaller small
smallest small
drier dry
driest dry
NLTK Lemmatizer handles adjectives with different endings very well.
Pros for lemmatization
- Using the base word ensures that the meaning behind the word is not lost
Cons for lemmatization
- Need to identify the part of speech
- Need to understand the fundamentals of linguistics thus more complex
B. Spacy Lemmatization
Spacy provides a lemmatization package. Let’s see how this package compares with NLTK lemmatization.
Spacy Lemmatization
In Spacy lemmatization, part of speech for each word is not a parameter.
# import spacy package
import spacy
# load English spacy
sp = spacy.load('en_core_web_sm')
# create word list
words = ['better','ran', 'are', 'running', 'were', 'shared', 'organize', 'university',
'awoken', 'arose', 'beheld', 'sped', 'withhold', 'flung', 'cats', 'timely', 'actively', 'tighter', 'smaller', 'farther', 'driest', 'farthest', 'loudly']
for i in words:
token = sp(i)
for word in token:
print(word.text,'-->', word.lemma_)
Output:
better –> well
ran –> run
are –> be
running –> run
were –> be
shared –> share
organize –> organize
university –> university
awoken –> awake
arose –> arise
beheld –> beheld
sped –> speed
withhold –> withhold
flung –> flung
cats –> cat
timely –> timely
actively –> actively
tighter –> tight
smaller –> small
farther –> far
driest –> dry
farthest –> farthest
loudly –> loudly
NLTK Lemamatizer
First I use nltk.pos_tag() to identify the part of speech for each word. This way, I can loop through each word when applying NLTK Lemmatizer. This is as well the method I would use for large Text Datasets in order to identify part of speech.
# create word list
words = ['better','ran', 'are', 'running', 'were', 'shared', 'organize', 'university',
'awoken', 'arose', 'beheld', 'sped', 'withhold', 'flung', 'cats', 'timely', 'actively', 'tighter', 'smaller', 'farther', 'driest', 'farthest', 'loudly']
#identify part of speech from word list
tags = nltk.pos_tag(words)
# create a list from part of speech
tag = list(dict(tags).values())
# rename part of speech parameter input in NLTK Lemmatizer
for i in range(0, len(tag)):
if tag[i] == 'JJR' or tag[i] == 'JJ' or tag[i] == 'JJS':
tag[i] = 'a'
elif tag[i] == 'VBP' or tag[i] == 'VBG' or tag[i] == 'VBD' or tag[i] == 'VBN':
tag[i] = 'v'
elif tag[i] == 'NN' or tag[i]== 'NNS':
tag[i] = 'n'
elif tag[i] == 'RB':
tag[i] = 'r'
else:
pass
# Create a new list with the word list and Part of speech
word_list = []
for i in range(0, len(tag)):
word_list.append([words[i], tag[i]])
# Loop to apply NLTK Lemmatizer
nltk_words = []
for word in word_list:
print(word[0],'-->', lem.lemmatize(word[0], pos = word[1]))
nltk_words.append(lem.lemmatize(word[0], pos = word[1]))
Output
better –> good
ran –> ran
are –> be
running –> run
were –> be
shared –> share
organize –> organize
university –> university
awoken –> awake
arose –> arose
beheld –> beheld
sped –> speed
withhold –> withhold
flung –> flung
cats –> cat
timely –> timely
actively –> actively
tighter –> tight
smaller –> small
farther –> farther
driest –> driest
farthest –> farthest
loudly –> loudly
Comparison
Spacy Lemmatization can identify the root word for verbs, plural, adjectives, and most adverbs, but cannot handle complex verbs such as words ‘flung’, ‘withhold’, and ‘beheld’. When setting the pos parameter to ‘v’, NLTK Lemmatizer changes flung to fling, however when I used NLTK.pos_tag() to identify part of speech, flung did not change. Other words that did not change because NLTK.pos_tag() did not correctly identify part of speech for driest, farther, arose, withhold, and beheld. NLTK.pos_tag() is necessary to use with NLTK Lemmatizer when working with thousands of documents.
References
Thomas, Rachel. “Topic Modeling with SVD & NMF (NLP Video 2).” YouTube, 8 July 2019, www.youtube.com/watch?v=tG3pUwmGjsc.
https://nlp.stanford.edu/IR-book/html/htmledition/stemming-and-lemmatization-1.html
Porter, Martin F. 1980. An algorithm for suffix stripping. Program 14 (3): 130-137.
http://www.nltk.org/_modules/nltk/stem/wordnet.html#WordNetLemmatizer
http://www.nltk.org/api/nltk.stem.html#nltk.stem.wordnet.WordNetLemmatizer.lemmatize